트랜스포머 알고리즘의 비약적인 경량화
Vision Transformer(ViT)는 2020년에 처음 출시된 이래 다양한 컴퓨터 비전 작업에서 놀라운 성능을 보여 왔습니다. 하지만 계산 복잡성과 지연 시간 문제로 인해 모바일 디바이스나 기타 리소스가 제한된 하드웨어에 배포하기가 어려웠습니다. 최근 논문인 "EfficientFormer: Vision Transformers at MobileNetSpeed"라는 논문에서 Snap과 노스이스턴 대학의 연구팀은 ViT 아키텍처에서 비효율적인 연산자를 식별하고 Transformer 아키텍처의 고성능을 유지하면서 경량 모바일넷 CNN만큼 빠르게 실행할 수 있는 새로운 ViT 설계 패러다임을 제안함으로써 이 문제를 해결했습니다.
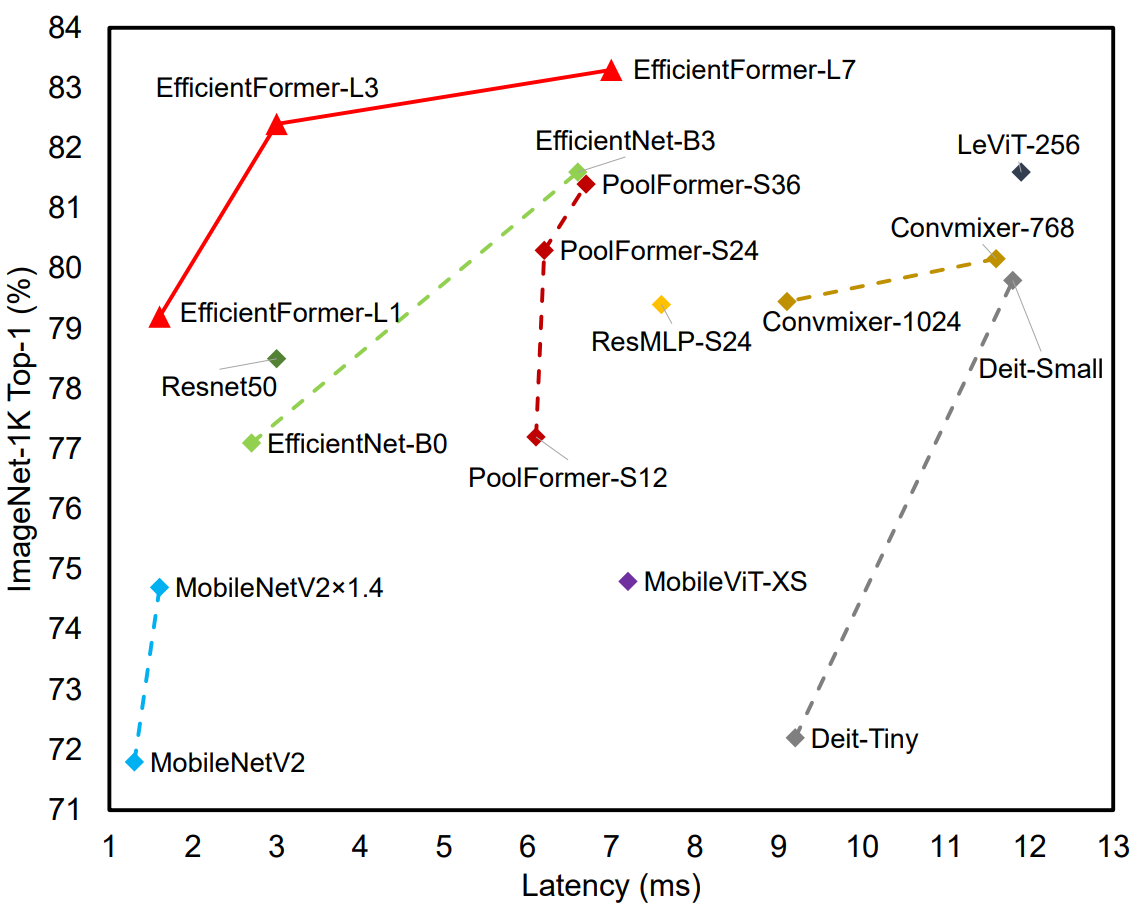
보시면 EfficientFormer-L1 Latency 수준이 MobileNetV2x1.4 버전 수준입니다. EfficientNet-B0보다 1ms 더 빠르네요. 성능은 더 높습니다.
EfficientFormer 구조

연구팀이 제안한 EfficientFormer는 패치 임베딩과 메타 Transformer 블록 스택으로 구성되며, 각 블록에는 불특정 토큰 믹서와 다층 퍼셉트론 블록이 포함되어 있습니다. 네트워크는 4단계로 구성되며, 각 단계는 임베딩 차원을 매핑하고 토큰 길이를 다운샘플링하는 임베딩 작업으로 사용됩니다. EfficientFormer는 Mobilenet 구조를 사용하지 않는 완전한 Transformer기반 모델입니다. 또한 연구팀은 간단하면서도 효과적인 그라데이션 기반 검색 알고리즘을 도입하여 EfficientFormer의 추론 속도를 최적화합니다.
연구팀은 실증 연구에서 이미지 분류, 물체 감지, 분할 작업에서 널리 사용되는 CNN 기반 모델 및 기존 ViT와 EfficientFormer를 비교했습니다. 그 결과, EfficientFormer는 기존 Transformer 모델과 대부분의 경쟁사 CNN을 능가하는 성능을 보였습니다. 가장 빠른 변형인 EfficientFormer-L1은 iPhone 12에서 1.6ms의 추론 지연 시간으로 ImageNet-1K에서 79.2%의 최고 정확도를 달성했으며, 가장 큰 변형인 EfficientFormer-L7은 7.0ms의 지연 시간으로 83.3%의 정확도를 달성했습니다.

이 연구는 ViT가 Transformer의 고성능을 유지하면서 모바일 디바이스에서 Mobilenet 속도를 달성할 수 있음을 보여줍니다. EfficientFormer 코드와 모델은 프로젝트의 깃허브와 'EfficientFormer' 논문에서 확인할 수 있습니다.
2023.03.15 - [AI설명] - microsoft visual chatgpt 출시 및 colab 사용법 가이드
2023.03.12 - [AI설명] - diffusion 모델 중 LoRA 모델에 대해 알아보고 이미지 생성해보기
2023.03.12 - [AI설명] - diffusion의 확장 모델인 dreambooth에 대해 알아보고 이미지 생성해보기
'노코딩AI > AI설명' 카테고리의 다른 글
| mAP, IOU란? Object Detection 성능 평가 지표 (0) | 2023.03.16 |
|---|---|
| microsoft visual chatgpt 출시 및 colab 사용법 가이드 (0) | 2023.03.15 |
| diffusion 모델 중 LoRA 모델에 대해 알아보고 이미지 생성해보기 (0) | 2023.03.12 |
| diffusion의 확장 모델인 dreambooth에 대해 알아보고 이미지 생성해보기 (0) | 2023.03.12 |
| 스테이블 디퓨전 Textual Inversion에 대해 속성으로 알아보도록 하겠습니다. (0) | 2023.03.11 |




댓글