
Dreambooth는 2022년에 Google 연구팀과 보스턴 대학교의 연구자들이 개발한 딥러닝 생성 모델입니다. Dreambooth는 기존의 텍스트-이미지 모델을 세부적으로 조정하거나 새로운 이미지를 생성할 수 있습니다. Dreambooth는 다른 디퓨전 모델(예: DALL.E 2, 미드저니, Stable Diffusion)이 할 수 없거나 부족한 것들을 할 수 있습니다.
Dreambooth는 사진부스와 비슷하지만, 한 번 주제를 캡처하면 꿈에서 볼 수 있는 곳 어디든 합성할 수 있다고 합니다. 예를 들어, 자신의 사진을 업로드하고 'as a full body shot of you in a suit’이라고 입력하면 Dreambooth가 자신의 사진을 바탕으로 정장 차림의 전신샷을 그리는 이미지를 생성합니다. 또한, 특정 캐릭터나 물건을 그리기 위해 추가 학습할 수도 있습니다.
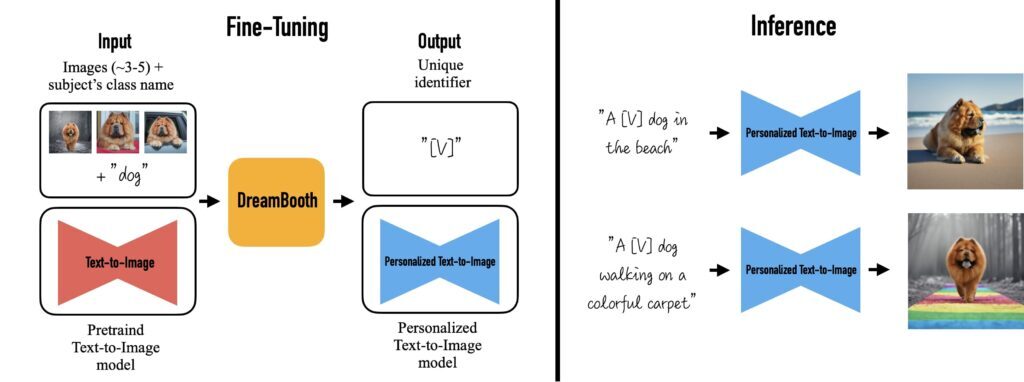
Dreambooth의 동작 구조
Dreambooth도 Textual inversion과 같이 몇 개의 이미지(일반적으로 3~5개)를 입력하면 DreamBooth는 조정된 이미지와 몇 가지 다른 Diffusion 모델을 사용하여 다양한 컨텍스트의 피사체 기반 개인화 이미지를 생성합니다.
이미지가 입력으로 제공되면 조정된 이미지 및 기타 Diffusion 모델이 고유 식별자를 찾아 피사체와 연결합니다. 추론할 때 고유 식별자는 다양한 컨텍스트에서 피사체를 합성하는 데 사용됩니다.
Dreambooth와 Textual Inversion의 차이점?
Dreambooth는 전체 모델을 미세 조정하는 반면, Textual Inversion은 희귀한 단어를 재사용하는 대신 새로운 단어를 삽입하고 모델의 일부에 포함된 텍스트만 미세 조정한다는 점에서 차이가 있습니다.
Dreambooth 수행해보기
먼저, 학습할 이미지 3장에서 5장정도 구해둡니다.
얼굴이 잘 나온 화면일 수록 좋습니다.
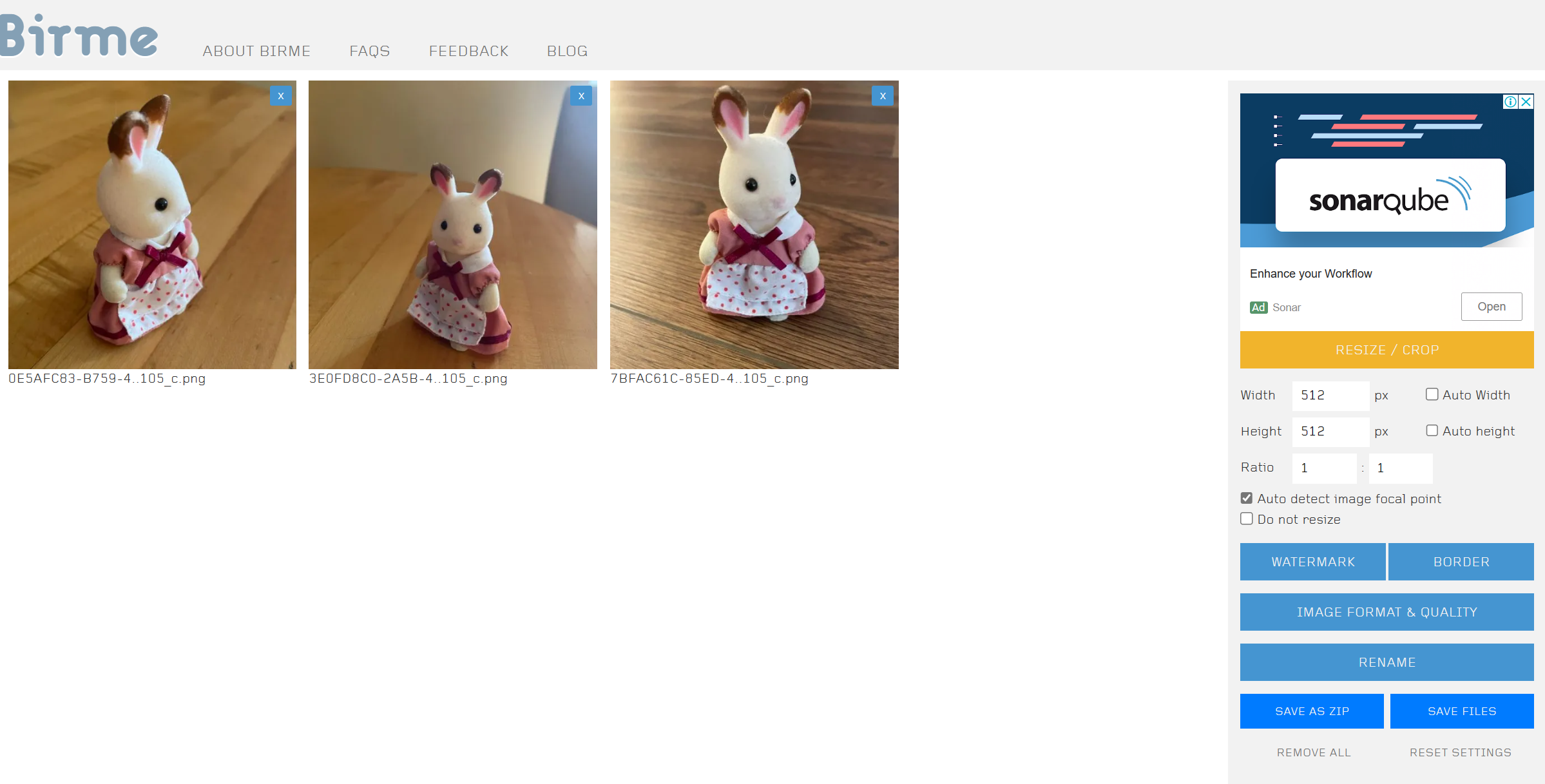
1. 이미지 크기 조정하기
훈련에 이미지를 사용하려면 먼저 v1 모델로 훈련할 수 있도록 512×512픽셀로 이미지 크기를 조정해야 합니다.
BIRME는 이미지 크기를 조정할 수 있는 편리한 사이트입니다.
BIRME - Bulk Image Resizing Made Easy 2.0 (Online & Free)
BIRME - Bulk Image Resizing Made Easy 2.0 (Online & Free)
About Birme New features in version 2 NEW* Added support for WebP format Now you can adjust the focal point of each photo individualy Auto load previous settings you used Auto focal point detection Renaming file names in bulk Save resized images as files i
www.birme.net
1) 이미지를 BIRME 페이지에 끌어다 놓습니다.
2) 각 이미지의 캔버스를 조정하여 피사체가 적절하게 보이도록 합니다.
3) 너비와 높이가 모두 512픽셀인지 확인합니다.
4) 파일 저장을 눌러 크기가 조정된 이미지를 컴퓨터에 저장합니다.
- 오른쪽 아래 Save Files를 클릭하면 컴퓨터에 저장됩니다.
이미지 출처:https://stable-diffusion-art.com/wp-content/uploads/2022/12/dreambooth_training_images.zip
2. Dreambooth 학습
오늘은 Google Colab을 사용해서 학습을 진행해보도록 하겠습니다.
Colab 코드는 다음을 참고해주시면 됩니다.
Colab은 사용할 줄 안다고 가정하고 오늘 진행하도록 하겠습니다.
DreamBooth_Stable_Diffusion_SDA.ipynb - Colaboratory (google.com)
DreamBooth_Stable_Diffusion_SDA.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
위의 Colab을 열고, 꼭 사본 저장하기를 해서 진행해주세요.
Colab 노트북을 열면 아래와 같은 DreamBooth에 대한 코드가 나올 겁니다.
그리고 왼쪽 재생 버튼을 누르면, 동그라미가 돌아가면서 실행이 될거구요.
Google Drive에 대한 로그인과 허가요청이 뜨면,
로그인을 해주시고 Allow 버튼을 눌러주시면 됩니다.
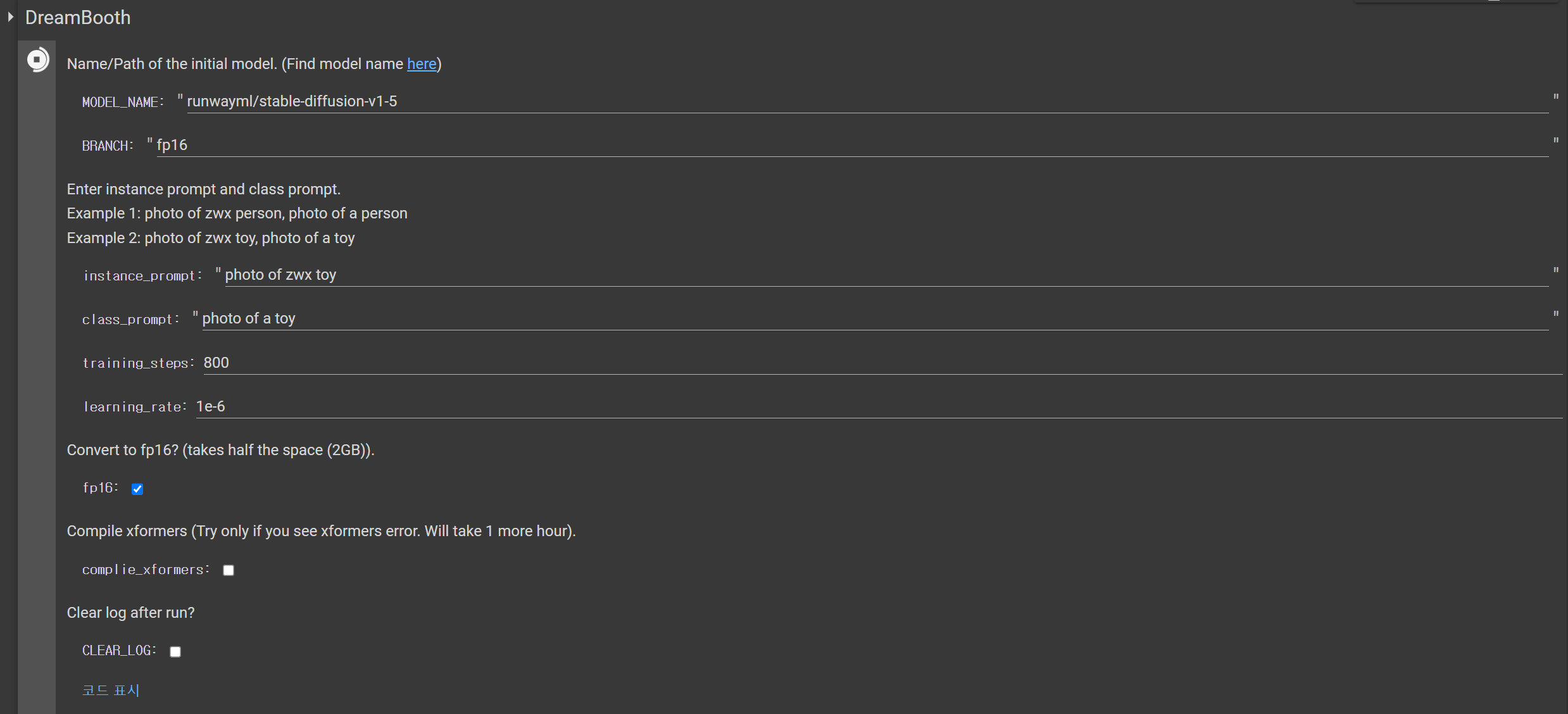
저희는 instance prompt를 photo of zwx toy
그리고 class prompt를 photo of a toy
라고 정했습니다.
그렇게 진행해 주시면 아래와 같이 이미지를 업로드하라는 메세지가 나올건데요

파일 선택을 누르시고, 아까 준비한 이미지를 모두 넣고 선택해주세요.
그러면 다음과 같이 설치가 막 진행이 될 겁니다.
설치하는데 시간이 꽤 걸립니다.
여유를 가지고 진행해주세요.
한 20~30분 정도 걸리는 것 같습니다.
그 후에는 이제 이미지를 생성해주는 건데요.
아까 설정한 객체인 zwx를 반고흐 이미지 풍으로 만들어 보겠습니다.
그리고 실행해보면,


위와 같은 반고흐 풍의 토끼그림이 나왔습니다.
오늘도 고생많으셨습니다.
2023.03.12 - [AI설명] - diffusion 모델 중 LoRA 모델에 대해 알아보고 이미지 생성해보기
2023.03.11 - [AI설명] - Diffusion 기술 중 Textual Inversion에 대해 속성으로 알아보도록 하겠습니다.
Diffusion 기술 중 Textual Inversion에 대해 속성으로 알아보도록 하겠습니다.
생성 커뮤니티에서 Stable Diffusion이 굉장히 핫해지고, 생성 AI에 대한 발전이 급속도로 이루어지고 있는데요. 그 중 하나가 Textual Inversion입니다. 아래는 논문으로 개제 된 정식 명칭인데요. An Image
nomadlabs.co.kr
2023.03.02 - [노코딩AI] - 실사 사진 생성을 위한 Stable Diffusion WebUI를 윈도우 PC에 설치하는 방법
실사 사진 생성을 위한 Stable Diffusion WebUI를 윈도우 PC에 설치하는 방법
Stable Diffusion을 WebUI를 활용해 PC에 설치하는 방법에 대해 알아보겠습니다. 설치를 완료하시면 아래와 같은 그림을 생성하실 수 있습니다. AI 모델을 변경하면서 애니 풍 사진, 실사 풍 사진, 반실
nomadlabs.co.kr
2023.03.03 - [노코딩AI] - 반실사 사진 만들기. Stable Diffusion WEB UI로 모델 합치는(Merge) 방법
'노코딩AI > AI설명' 카테고리의 다른 글
| microsoft visual chatgpt 출시 및 colab 사용법 가이드 (0) | 2023.03.15 |
|---|---|
| diffusion 모델 중 LoRA 모델에 대해 알아보고 이미지 생성해보기 (0) | 2023.03.12 |
| 스테이블 디퓨전 Textual Inversion에 대해 속성으로 알아보도록 하겠습니다. (0) | 2023.03.11 |
| 확장자에 ckpt 말고 safetensors가 붙는 이유는 뭘까? safetensors란? (0) | 2023.03.04 |
| 인공지능과 딥러닝은 무엇이 다른가요? 인공지능과 딥러닝의 차이 (0) | 2023.02.15 |




댓글