생성 커뮤니티에서 Stable Diffusion이 굉장히 핫해지고,
생성 AI에 대한 발전이 급속도로 이루어지고 있는데요.
그 중 하나가 Textual Inversion입니다.
아래는 논문으로 개제 된 정식 명칭인데요.
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
텍스트 반전을 이용해서, 개인화 된 텍스트 투 이미지 생성을 하겠다라는 목표를 가지고 있습니다.
여기에는 기존의 Latent Diffusion Models을 사용했다고 언급 했구요.
미리 학습 되어 있는 텍스트-이미지 모델(Latent DIffusion Models)의 임베딩 공간에 새로운 '단어'를 사용하여 개인 사물이나 예술적 스타일과 같은 특정 개념을 생성하는 방법을 학습한다고 합니다. 그리고 이 새롭게 생성한 새 '단어'를 이용하여 다른 문장에 이용할 수 있게 한다는 겁니다.
아래는 S*라는 새로운 단어를 객체화 시켰는데요.
맨 왼쪽에 있는 샘플 그림 3~4개가 S*라고 보시면 됩니다.
이러한 객체 S*를 기존에 있는 Text에 입력해서 사진을 합성하는 거라고 보시면 될 것 같습니다.
아래 Elmo 사진이랑 S* 합성된 걸 보시면, Elmo 포즈가 S*가 하고 있는 포즈를 취하고 있죠?

아래 사진 역시 간달프와 고양이를 합성한 그림으로 보여집니다.
텍스트 반전은 새 텍스트 토큰에 대한 토큰 임베딩을 학습하여 작동하며, Stable Diffusion의 나머지 구성 요소는 고정된 상태로 유지합니다.

아래 사진은 무슨 객체인지 모르겠네요. 어쨌든 S*이라는 왼쪽 Input samples를 학습해서 기존에 있는 Sport car나 lego를 S* 객체화를 시킨 모습입니다.

동작하는 모델 구조는 다음과 같습니다.
대부분의 텍스트-이미지 변환 모델과 같이, Textual Inversion 또한 텍스트 인코딩 단계에서 첫 번째 단계는 프롬프트를 숫자 표현으로 변환하는 작업을 수행합니다. 이는 일반적으로 단어를 토큰으로 변환하는 방식으로 수행되며, 각 토큰은 모델 사전의 항목에 해당합니다.
그런 다음 이러한 항목은 특정 토큰에 대한 연속 벡터 표현인 '임베딩'으로 변환됩니다. 이러한 임베딩은 일반적으로 훈련 과정의 일부로 학습됩니다. Textual Inversion에서도 사용자가 제공한 특정 시각적 개념을 나타내는 새로운 임베딩을 찾아냅니다. 그런 다음 이러한 임베딩은 새로운 의사 단어에 연결되며, 다른 단어처럼 새로운 문장에 통합될 수 있습니다. 어떤 의미에서 우리는 프로즌 모델의 텍스트 임베딩 공간으로 반전을 수행하고 있는 것입니다. 우리는 이 과정을 '텍스트 반전'이라고 부릅니다.
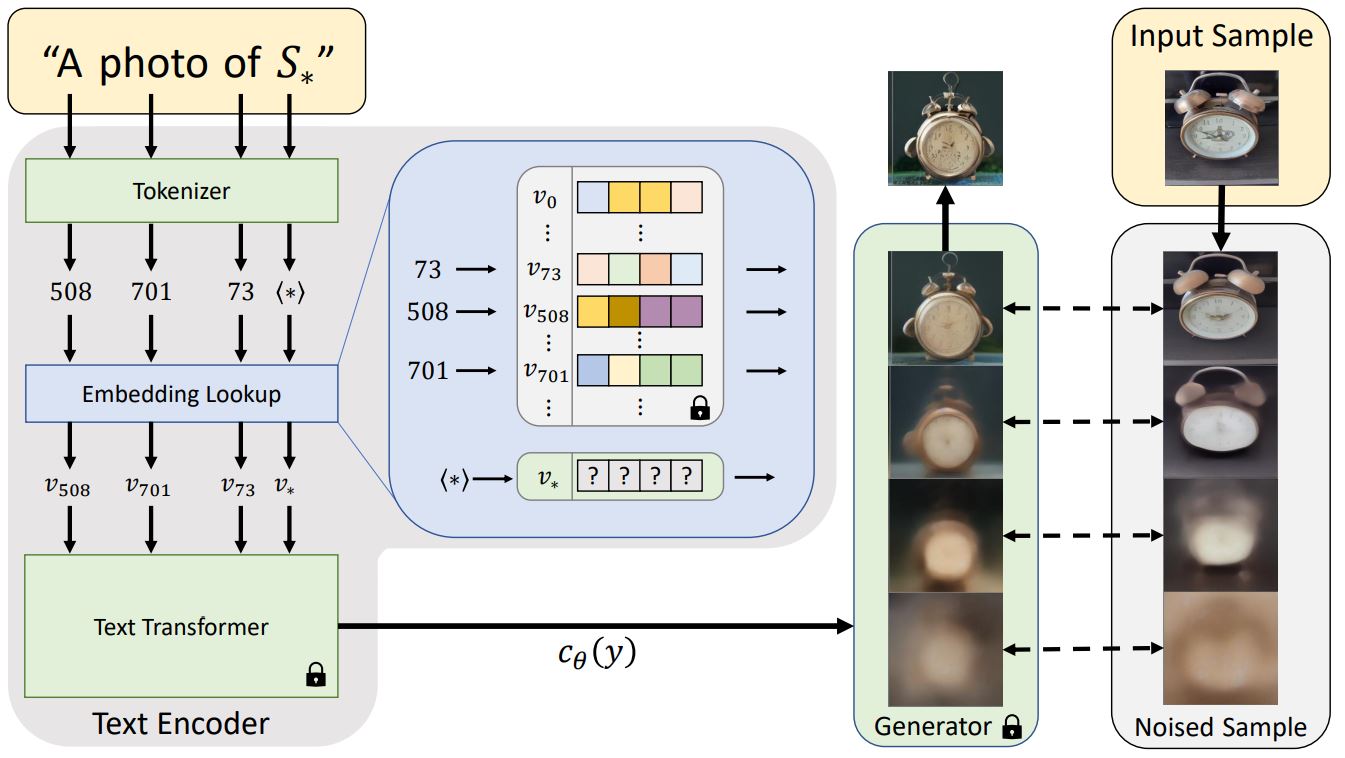
그러니까, 간단하게 설명하면 새로운 객체 S*를 하나 추가 학습을 시키구요.
S*의 특징점을 학습해서 넌 S*야 라고 만들어 놓습니다.
그리고 문장에 S*를 같이 넣어주면, AI가 S*를 포함해서 문장의 맥락을 형성하기 때문에
이미지가 생성될 때 텍스트에 있는 S*도 영향을 미치게 된다.
라고 보시면 될 것 같습니다.
여기에는 문제점도 있습니다.
모든 인공지능 모델에는 편향(Bias)가 생길 수 있습니다.
텍스트-이미지 모델 또한 마찬가집니다.
텍스트-이미지 모델은 학습 데이터에서 물려받은 편향으로 인해 어려움을 겪을 수 있습니다. 새로운 개념을 학습하는 대신 '편향된' 개념에 대한 새로운 임베딩을 찾을 수 있습니다. 이러한 임베딩은 작은 데이터 세트를 사용하여 찾을 수 있으므로 데이터를 쉽게 큐레이팅하고 더 공정한 표현을 보장할 수 있습니다.
왼쪽 기본모델에서 doctor라고 했을 때, 데이터 세트가 너무 적어서 그런지 제대로 생성이 안되는걸 보실 수 있죠?
그래서, S*로 추가 의사자료를 학습 시키고, S*로 제대로 된 의사를 생성할 수 있습니다.
오른쪽에서 Doctor란 text를 안쓰고 S*로 학습된 Doctor를 생성하니까 훨씬 이미지가 잘나왔죠?

그리고 원하는 타겟 이미지만 마스킹해서, 이미지 생성하도록 도울 수 있습니다.

많은 도움이 되셨으면 좋겠습니다.
2023.03.12 - [노코딩AI/AI설명] - diffusion 모델 중 LoRA 모델에 대해 알아보고 이미지 생성해보기
diffusion 모델 중 LoRA 모델에 대해 알아보고 이미지 생성해보기
오늘은 LoRA 모델에 대해서 알아보고 WebUI로 직접 구현하는 시간을 가져보겠습니다. LoRA 모델은 표준 체크포인트 모델에 작은 변경 사항을 적용하는 소규모 안정적 확산 모델입니다. 일반적으로
nomadlabs.tistory.com
2023.03.12 - [노코딩AI/AI설명] - diffusion의 확장 모델인 dreambooth에 대해 알아보고 이미지 생성해보기
diffusion의 확장 모델인 dreambooth에 대해 알아보고 이미지 생성해보기
Dreambooth는 2022년에 Google 연구팀과 보스턴 대학교의 연구자들이 개발한 딥러닝 생성 모델입니다. Dreambooth는 기존의 텍스트-이미지 모델을 세부적으로 조정하거나 새로운 이미지를 생성할 수 있
nomadlabs.tistory.com
https://textual-inversion.github.io/
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Text-to-image models suffer from biases inherited from the training data. Rather than learning a new concept, we can find new embeddings for 'biased' concepts. These are found using small datasets, so we can easily curate the data and ensure a fairer repre
textual-inversion.github.io
'노코딩AI > AI설명' 카테고리의 다른 글
| diffusion 모델 중 LoRA 모델에 대해 알아보고 이미지 생성해보기 (0) | 2023.03.12 |
|---|---|
| diffusion의 확장 모델인 dreambooth에 대해 알아보고 이미지 생성해보기 (0) | 2023.03.12 |
| 확장자에 ckpt 말고 safetensors가 붙는 이유는 뭘까? safetensors란? (0) | 2023.03.04 |
| 인공지능과 딥러닝은 무엇이 다른가요? 인공지능과 딥러닝의 차이 (0) | 2023.02.15 |
| 인공 지능이란 무엇인가? 인공지능에 대해 알아보도록 하겠습니다. (0) | 2023.02.15 |




댓글